

La Biblioteca de Babel está recorrida por una serie inacabable de galerías idénticas, hexagonales. En cada pared hay cinco anaqueles; en cada anaquel, treinta y dos libros. Cada libro tiene cuatrocientas diez páginas. Cada página, cuarenta renglones. Cada renglón, unas ochenta letras. El alfabeto es mínimo: veintidós letras más el espacio, la coma y el punto.
La biblioteca está cruzada por escaleras que suben y bajan sin fin, lámparas débiles y espejos. Y hombres que nacen, recorren, buscan y mueren entre sus volúmenes. Todos buscan su libro. Libros idénticos en forma, pero todos distintos en contenido. No hay dos iguales. Están todos los libros que pueden escribirse: los verdaderos y los falsos; están todas las historias y todas las mentiras; las profecías y su refutación. Es el catálogo fiel de todo lo que existe en el universo.
Suena a paraíso, pero es una condena. Porque la biblioteca no tiene orden. No existe un catálogo. El libro que buscas existe en algún hexágono, pero localizarlo es casi imposible. Sus bibliotecarios envejecen en los pasillos. Muchos enloquecen. Algunos se arrojan por los pozos de ventilación. Porque si la biblioteca contiene todos los libros posibles, entonces en algún hexágono existe, necesariamente, el que cuenta cómo y cuándo será tu muerte. Pero ese libro verdadero está junto a todas las versiones falsas que cuenta también tu muerte, todas con la misma encuadernación, todas con cuatrocientas diez páginas, y no hay forma de saber cuál es la auténtica.
El cuento que quizá recordamos mal
Ese es el cuento de Borges que casi todo el mundo recuerda mal. Se cita Babel como metáfora de la abundancia (internet, el exceso de información). Pero lo aterrador de la biblioteca no era la abundancia. Era la imposibilidad de encontrar. ¿Existe mayor frustración que tener «todos los libros» y, por tanto, la solución a todos los problemas, pero no poder encontrarlos?
Cuando leí el cuento la primera vez, no entendí qué eran esos veinticinco símbolos. El otro día tuve una idea loca: son los equivalentes de los bits. Borges intuyó en 1941 la idea que fundaría la era digital: que todo lo expresable cabe en permutaciones de un alfabeto finito. Sus veinticinco signos son como el cero y el uno; los dieciséis del hexadecimal, los doscientos cincuenta y seis de un byte. Cualquier texto, imagen o canción que hayas visto en la pantalla de tu computadora es simplemente un renglón de una página de un libro de Babel. Una cadena finita sobre un alfabeto finito. Borges nos dibujó el universo digital antes de que existiera el primer ordenador.
La era digital hizo real la biblioteca de Borges. Pero solo como almacén. Llenamos los discos de permutaciones de ceros y unos (archivos, copias de seguridad, versiones) y reprodujimos el problema original a otra escala: lo tenemos todo guardado y seguimos sin encontrar nada. Internet es el almacén infinito de libros sin catalogar. Buscadores, desde el AltaVista de 1995 al Google actual, cada vez más sofisticados, intentaron poner orden, y aun así seguimos perdidos la mayor parte del tiempo.
Y es que el almacén nunca fue lo difícil de Babel. Lo difícil era el orden. El drama es que el espacio no tiene mapa. Ahí está la diferencia: lo que hace un LLM de frontera no es guardar Babel. Es generarla.
dhcmrlchtdj
Sobre la IA circula una idea falsa: que escribe por simple permutación, combinando símbolos hasta que sale algo. No. Una máquina que permuta al azar produce una sola cosa: ruido. Son los infinitos monos tecleando en una máquina de escribir, esperando que salga «El Quijote«. Eso es exactamente el 99,99% de los libros de Babel: un embrollo incomprensible, esas «obras que no difieren sino por una letra o por una coma» de las que nos avisa Borges. Si un LLM funcionara así, no serviría para nada.
El modelo hace lo contrario de permutar a ciegas. Ha aprendido una ponderación, destilada tras la revisión de miles de millones de textos humanos, que hace enormemente más probable generar el libro legible que el ruido. Cuando le preguntas algo, la IA no rebusca en los estantes. Calcula, palabra a palabra, cuál es la continuación más probable, y traza un sendero en la parte iluminada de Babel. Es la biblioteca total con lo que no tenían los bibliotecarios de Borges: un sendero de migas de pan que nos lleva por dónde están los libros que se pueden leer. Borges nos contaba que incluso algo como «dhcmrlchtdj«, que parecen letras al azar, puede encerrar, «en alguna de sus lenguas secretas«, sentido.
Y es que el LLM improvisa cada vez que le preguntas. Hazle la misma pregunta dos veces y tomará caminos distintos: hay un margen de azar deliberado en el proceso, una dosis xontrolada de lanzamiento de dados. Pídele que responda sobre lo mismo fingiendo ser un rey y luego un mendigo, y observa el resultado. No te recita un libro que estaba en un estante. Escribe uno nuevo, sobre la marcha, guiado por la pendiente de probabilidades. Esa es la diferencia exacta entre la Babel de Borges y la Babel generativa. La primera es un archivo: el libro ya existe, inmóvil, esperando a un lector que casi nunca llega. La segunda es un acto: el libro se produce en el instante en que lo pides, y no existía antes de que preguntaras. Los LLM siguen escribiendo la Biblioteca de Babel todos los días.
Babel no necesitaba más libros. Necesitaba un orden

Los LLM no son máquinas que lo saben todo. Solo han leído mucho y recuerdan algo, pero saben dónde está lo coherente. Yo los uso así todos los días: no como un oráculo, sino como el bibliotecario que Borges nunca tuvo, el que te lleva en segundos al pasillo correcto en lugar de dejarte envejecer en el equivocado. Treinta años buscando soluciones a problemas me dicen que esa capacidad de navegar lo inabarcable es exactamente lo que necesitamos. No me angustia. Me estimula.
Conviene, eso sí, entender qué ordena el modelo y qué no. Y aquí hay que matizar lo de la permutación. El sendero de migas de pan corre en una sola dirección: la de lo coherente. Hace más probable un texto con sentido que un galimatías. Pero el de la verdad es otro sendero y por él no hay necesariamente ninguna miga. Sobre lo coherente, el modelo sabe muchísimo. Sobre lo cierto sabe poco, porque la verdad no es la variable sobre la que aprendió a optimizar. No es que tome el camino equivocado hacia la verdad: es que hacia la verdad no trazó ningún camino.
Así que, en realidad, la permutación no desaparece del todo. Se esconde, en el sendero que el orden no cubre. Dentro de lo que ha leído, un LLM combina con libertad lo verdadero y lo falso, porque para él tienen el mismo aspecto y parecida probabilidad de salir. Esa permutación residual (un texto coherente, bien encuadernado, sin vínculo necesario de la verdad) tiene un nombre que se ha vuelto familiar: alucinación. No es un libro de ruido. Es un libro perfecto de un estante falso. Y por fuera no se distingue del verdadero: misma tipografía, mismas cuatrocientas diez páginas.
Ahora es Borges frente a la máquina. Aunque «dhcmrlchtdj» parece un sinsentido, esconde sentido: en alguna lengua secreta, nos avisó Borges, significa algo. La alucinación es su reflejo invertido: parece tener sentido pero nos esconde su falta de verdad. Una esconde el significado bajo apariencia de ruido; la otra esconde el vacío bajo apariencia de significado. Algo como «dhcmrlchtdj» lleva escrito en la cara que necesita una clave, que hay que descifrarlo, que falta trabajo. La alucinación nos miente en eso. Ya no es la verdad escondida bajo el ruido, sino la falsedad bajo prosa impecable, servida descifrada y cierta. Desactiva tu intuición. Lo que se anuncia como incomprensible avisa con honestidad. Lo falso que se muestra como verdadero no pide nada, y por eso nadie lo comprueba. Misma biblioteca, pero ahora el LLM te conduce derecho al libro falso y te lo narra con voz de respuesta certera.
El mapa es de verosimilitud, no de verdad
En un working paper reciente de investigadores de UCLA y MIT Sloan, Some Simple Economics of AGI, Christian Catalini (MIT), Xiang Hui y Jane Wu formulan todo esto en términos económicos: a medida que generar se vuelve abundante y barato (lo que algunos llaman una commodity), el valor se desplaza hacia otra cosa. Hacia la verificación. El cuello de botella ya no es escribir. Es validar. Ahora producimos texto, código y análisis mucho más rápido de lo que cuesta comprobar si son siquiera correctos, no digamos verdaderos. Y comprobar sigue atado a algo que no escala con los chips: la cognición humana, el criterio, la experiencia que avala lo que la máquina ejecuta.
Catalini, Hui y Wu le ponen nombre al peligro de saltarse ese paso: «el caballo de Troya«. Una salida que cumple con todas las métricas que mides, que parece trabajo productivo y que esconde el riesgo precisamente en lo que no mediste. El informe que pasa la inspección y falla donde nadie miró. Después de toda la vida cazando fallos invisibles como ingeniero, te confirmo que es el mismo fallo de siempre, pero ahora generado a escala industrial. En ese mapa de puntos rojos, verdes y azules que se encuentra en el paper (y que fue bastante viral) cada tarea se ordena por lo que cuesta ejecutarla (eje horizontal) frente a lo que cuesta verificarla (eje vertical). La esquina peligrosa está arriba a la izquierda; ahí la máquina genera casi gratis y nadie lo puede comprobar: el territorio del caballo de Troya.
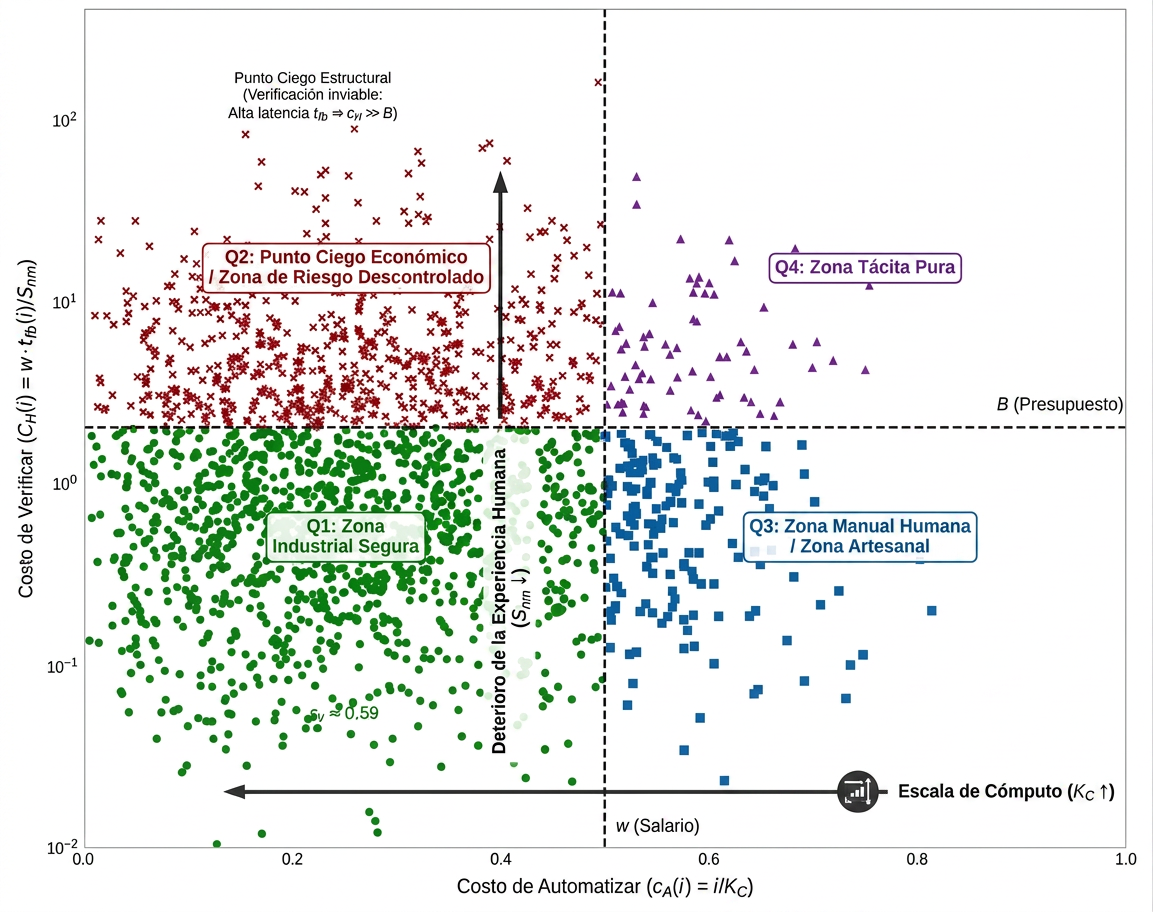
Todo esto, honestamente, no me parece una amenaza: me parece el reconocimiento de dónde estuvo el siempre valor: en el oficio. Ningún ingeniero firma un cálculo porque la herramienta sea buena; lo firma porque comprobó el número que sostiene la estructura. Yo verifico el dato que soporta un informe, y lo hacía también antes de la IA, cuando la fuente era un colega de confianza, un vademécum o un manual con tapas. Eso no ha cambiado. Lo que cambia es el coste: generar nunca fue tan barato, y validar nunca fue tan caro. El bibliotecario que sabe distinguir el libro verdadero del falso, cuando los dos tienen la misma encuadernación y las mismas páginas, acaba de convertirse en el más valioso de Babel. La diferencia entre verosímil y verdadero es casi siempre pequeña. Pero esa diferencia puede ser enorme cuando hay que decidir.
Los bibliotecarios de Borges habrían dado la vida por esto. Buscaron durante generaciones el catálogo de catálogos: el libro que ordenaría a todos los demás; pero murieron sin encontrarlo, convencidos de que el orden no existía en ninguna parte. Se equivocaban en lo esencial. El orden no estaba en ningún estante, perdido entre el ruido. No era algo que encontrar: era algo que se podía generar con el orden que nosotros queramos y las veces que queramos.
Lo que ninguna máquina nos ha quitado todavía es lo otro. Saber leer. Distinguir, entre dos libros idénticos por fuera, cuál dice la verdad. Babel hoy se escribe a sí misma. Leerla sigue siendo nuestro.
«Mi soledad se alegra con esa elegante esperanza».

